You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
对于bns配置,取其Noah 上的 group 服务组包含的服务单元的后缀。比如group.raltest.ksarch.cn 这个组下面挂着echo.ksarch.cq和 echo.ksarch.tc 这两个服务单元,那么第一个服务单元内的所有机器都属于cq,第二个服务单元内的所有机器都属于tc。虽然配在 group 上,但是 group 本身的名字没有影响。

简介
全称 Resource Access Layer。以 PHP 扩展的方式提供一个客户端,实现了对后端服务端交互的支持,用户在添加相应服务配置后,即可使用 RAL 一站式接口与后端服务进行交互,而不需要关注数据格式处理与协议交互的过程,为后端交互提供简单可依赖的支持。
特点
配置文件
Local配置
打包格式
$payload = array( 'user' => 'tom', 'love' => array( 'first' => 'lily', 'second' => 'anna' ) );
如果是 "post" 方式发送的,后端收到的 $_POST 请求是
array( 'user' => 'tom', 'love' => '{"first":"lily","second":"anna"}` );
WebFoot配置
IDC匹配规则
IDC MAPPING
只支持配在 Webfoot 的“group”(服务组)节点,配在服务单元里不起作用。它提供了一种机房间切流量的方案。
如果服务组的配置中 idc_map 字段存在,且 Hybrid (全混连)关闭的情况下,会启用 idc_map,因为全混连会让所有的后端机器都可见。如果 idc_map 字段不存在,则请求时,只选择与前端同机房的后端去交互。
Webfoot 服务,在 Noah 上的 group 节点上可以有这样的配置:
在本例中,idc_map 配置的第一条 map,(key 中的)"jx" 表示调用者的机器的机房,(prefer里的)"cq" 表示 Noah 上的 group 服务组包含的服务单元的后缀,即所有被调用者的机器的机房。也就是说,如果 group.raltest.ksarch.cn 这个组下面挂着 echo.ksarch.cq 和 echo.ksarch.tc 这两个服务单元,那么第一个服务单元内的所有机器都属于 cq,第二个服务单元内的所有机器都属于 tc。虽然配在 group 上,但是 group 本身的名字,后缀是 all 呢,还是 cn,对 RAL 均没有影响。
整个第一条 map 的意思是,将来自 jx 机房的请求,引流到 cq 机房的后端。
第二条 map 规则中,prefer 还可以支持数组,请注意,数组需要用方括号括起来。idc_map 大小写敏感,机房名字用小写。prefer 中的 "self" 关键字,会被替换成 key 中的 idc。目前的实现,"prefer" 字段必须,"backup" 字段可选(2.0.10.0以后版本支持)。
第三条规则中,"all" 关键字则会对本次请求临时打开全混连,来自 "tc" 的流量,会按负载均衡规则分发到后端所有的机器。
第四条规则中,key 是 "default",意思是所有没有在上面出现过的 IDC 都会走这条 map 规则,map 到 "jx" 机房和自身。
IDC Mapping 的功能影响 ral()、ral_multi()、ral_get_service() 三个接口。
负载均衡的过程
负载均衡需要解决的问题
RAL的负载均衡目前支持的功能:
均衡策略
对每一次负载均衡处理,均衡过程首先会对一个服务多个实例的优先级进行排序,一次请求的均衡过程如下:
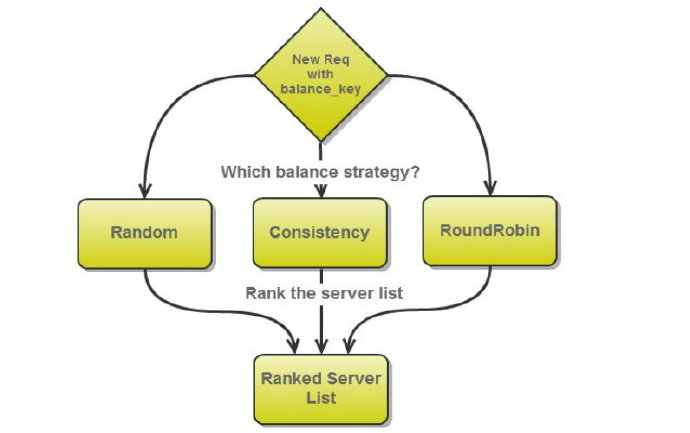
每次请求的均衡过程会对后端实例进行打分,来决定本次请求优先级顺序。服务实例选择不会立刻选择最高优先级,随后的健康检查和流量切分等过程还会对其进行淘汰,最终在符合要求的实例中按优先级进行选择。
下面将分别对RAL目前的3种均衡策略一一介绍。
随机
随机(Random)是最传统的均衡方式,每个服务实例得分通过随机的方式获取。
这种方式服务请求会比较均匀的分配到不同的实例上,以保证后端机器资源使用比较均匀,避免某台机器压力过大而导致服务不稳定。这种方式也是最常使用的一种均衡策略。
一致性HASH
一致性hash(consistency)的均衡策略常用于存在cache的服务,对于这类服务均衡时需考虑其cache命中率,特定的请求应尽可能的映射到同一台机器。
使用Hash的方式做均衡时,还要考虑以下2点:
RAL负载均衡使用一致性hash,通过上层指定的balance_key进行均衡,对于给定的balance_key,将与各服务实例结合一并进行md5签名,并对结果排序,以确定优先级顺序。
这里使用md5做hash提高均衡性,避免多个balance_key在hash后的结果冲突,使不同balance_key的请求后尽可能落到不同的实例。当然,对于相同的balance_key则会落在同一实例。 另外,均衡时会对每个服务实例的得分进行排序来以保证单调性,以避免添加和摘除服务实例后出现大量请求cache失效的问题。添加和删除实例时,仅影响之前落到相邻的实例的请求,而不会影响到其他请求。
排序时,每个机器实例得分具体计算方式如下:md5(server_ip + server_port + balance_key) 即每个server的ip和port加上balance_key,三者做字符串拼接后再做md5签名。
轮询
轮询也是一种比较传统的均衡方式。这种均衡方式,可以确保对后端服务实例的访问在任何时刻都是非常均匀的。 考虑到还有健康检查都处理流程,轮询策略并不会直接确定本次请求的实例,只保本次轮询到的实例具有最高优先级。在计算优先级得分时,是按照以下方式进行:
均衡时确保每次轮询到的server实例得分最高,其它机器则退化为随机取模的方式计算均衡得分:
本期轮询到server实例得分:N + 1
其它实例得分:rand() % N
最后根据得分对均衡的优先级进行排序,以保证轮询到的机器具有最高优先级,其他实例优先级随机排序。
根据连接健康状态选择
在经过均衡策略处理后,每个服务实例的优先级将按照从高到低的顺序排列,其后将根据连接健康状态进行选择。这里要做的其实就是对连接健康状态异常的机器进行淘汰。

对每个实例的连接状态都需要进行记录,以判断该机器的健康状态,实现时会为每个服务实例都维护一个连接状态的队列,记录最近一段时间的连接情况。当然这个队列的长度是可以进行配置的,也就是ral配置文件中的ConnectQueueSize。每次有连接失败的情况进队,失败计数加一,失败状态出队时,则连接失败次数减一。
X轴表示连接失败次数,Y轴表示连接健康状态(100%为正常)
从上图可以看出,队列(长度为ConnectQueueSize)中失败次数与健康状态的关系,在连续多次失败时,一旦队列中的失败次数超过P点的X坐标,健康状态便会降到最低。这里K点及P点的坐标在RAL中都有其对应的配置:
ConnectX1 : 10 (K点X坐标)
ConnectY1 : 95 (K点Y坐标)
ConnectX2 : 40 (P点X坐标)
ConnectY2 : 5 (P点Y坐标)
最后根据连接健康状态进行选择,健康得分就是该实例的选择概率,健康得分越低淘汰的概率也就越大。
另外,需要注意的是,RAL中要使这个队列生效,需要运行在php-cgi的情况下,因为对于CLI方式,每次执行PHP连接健康状态的队列每次都会被重新初始化,从而无法保留状态信息。
根据读取健康状态选择
在根据连接健康状态进行选择后,连接异常的实例已经历过一次淘汰了。
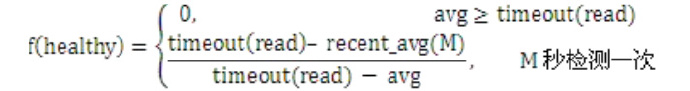
负载均衡并未就此结束,对于一个稳定运行的服务实例,其时处理时间也应当收敛。 基于这点考虑,负载均衡还进一步支持根据服务访问的健康状态进行选择淘汰。 这里需要注意的是, 读取健康状态的判断是建立在服务处理时间收敛的基础上。对于稳定运行时处理时间不收敛的服务,该过程并不适合。
为了记录每个实例处理时间的历史状态,负载均衡会为每个实例都维护一个读取时间的队列,该队列保留过去一段时间内的状态,这里保留多久也是支持配置的,配置项为:HealthyQueueSize。 那么已经知道了最近一段时间内服务读取的时间,该如何进一步计算读取的健康状态呢,这里的思路如下:
每隔一段时间(M秒)计算该时间段内读取的平均时间,即上述的recent_avg(M)。将该平均时间与队列中总的平均处理时间进行比较,如果M秒内出现波动且耗时增加,健康状态便会有所降低,而耗时减少健康状态则会提高。但如果服务确实耗时增加且整体处理时间又稳定下来,那么经过一段时间,健康状态又会收敛到正常水平。
上式的间隔时间M和健康超时时间timeout(read)都可在配置文件中指定,对应的配置项分别是:HealthyCheckTime和HealthyTimeout。如果无HealthyTimeout配置则不启用读取健康状态选择。 得到健康得分f(healthy)后,选择或淘汰将按如下方式进行(其中R是选择概率的最小值,对应配置项是HealthyMinRate):
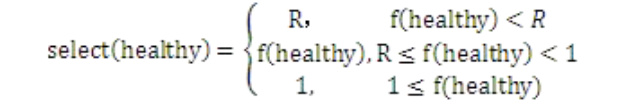
根据机器处理能力进行选择
在经过了前面两步健康选择和淘汰的过程后,负载均衡会进一步考虑根据机器的处理能力对请求进行分流,即流量切分。 当后端某个实例的性能过低时,应该考虑将流量切分给性能更好机器。至于性能差距在多大时考虑流量切分,可以通过配置HealthyBackupThreshold来指定流量切分阈值。 那么首先面临的问题是:该如何定义某个机器实例的性能呢?
可以通过该实例的平均处理时间来判断,即1/avgtime。 在获取机器实例性能的基础上,就可以对其进行流量切分,尽可能的将请求分配到性能更好的实例去处理,切分思路如下:
这里可以看到,即使有一些服务实例处理时间较长或网络延迟较大,通过负载均衡的切流量就可以避免请求延迟较大的服务实例,使服务整体对外的性能较优。
最终选择
在负载均衡经历了以上三个选择过程后,常规的负载均衡过程就以完成,这时已经能够确定本次交互优先选择的服务实例。
不过除了以上功能,负载均衡还支持进行跨机房访问。 考虑到有时服务会分机房部署,为降低网络延迟及带宽成本会优先请求当前机房的机器。当单边机房不稳定或宕机的情况下,为了避免拒绝服务,可以配置尝试跨机房。服务可通过CrossRoom配置开启跨机房。
在后端实例配置了机房且启用跨机房,那么当前机房的实例在经过以上三种状态选择被淘汰时,便可尝试跨机房去请求其他机房的实例。 如果不启用跨机房,便会在经历过以上选择淘汰的结果中,选择最高优先级且未因健康状态被淘汰的那个实例。
The text was updated successfully, but these errors were encountered: