
概念
- 散列技术: 在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key) , 通过查找关键字, 不需要比较就可获得记录的存储位置;
存储位置 = f(关键字)
- 散列表或哈希表: 采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(HashTable);
- HashTable是一种存储数据的结构,就是用一个key对应一个value,我们可以通过key来查询这个value值。
- 通过Hash函数 f(关键字value)计算处理,将关键字保存,并返回一个自定义的存储位置 key;
- 查询的时候和以上第二步计算位置的方式一样,通过Hash函数 f(关键字value) 返回存储位置,只是在查询的时候不用做保存数据操作而已;
- 具体可以参见:简单HashTable原理
- Hash函数:传一个value值给这个函数,这个函数对其进行保存,并把保存的位置key返回给调用方。这是HashTable的构造过程。
- 散列地址: 关键字对应的记录存储位置, 也就是以上HashTable中所说的key;
散列技术的特性
- 既是一种存储方法,也是一种查找方法;
- 数据元素之间无罗辑关系,所以不适合范围查找,不适合查找同样关键字的记录,不适合获取记录的排序,最值等操作;
散列函数的构造
- 原则:(1) 计算简单; (2)散列地址分布均匀
直接定址法
f(key) = a*key+b; ( a,b为常量 )
- 背景: 知道关键字的分布;
- 取关键字的某个线性函数值作为散列地址;
- 特点:简单,均匀,不会冲突,但是事先知道关键字的分布情况,适合查找表小且连续。
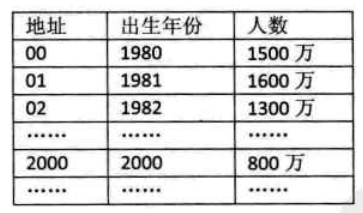
- 举例:比如统计1980年以后出生的人数:
-
f(key) = key-1980;
数字分析法
- 背景: 关键字位数多,知道关键字分布;
-
比如手机号,可能前几位一样,只是后几位不同,抽取关键字的一部分计算散列存储位置。事先知道关键字分布且若干位分布均匀。
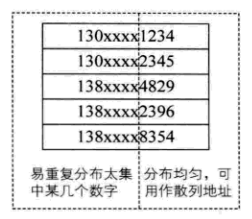
- 对手机号的后4位做特殊处理,比如:
- 翻转: 1234=>4321
- 叠加: 1234=>12+34=46,等等;
平方取中法
- 背景: 不知道关键字分布,且位数不是很大。
- 比如: 1234,平方1522756,抽取中间227作为散列地址。
折叠法
- 背景: 不知道关键字分布,位数多。
- 从左到右分割成位数相等的几部分,这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
- 比如: 关键字是 9876543210, 散列表长为3; 将关键字分为4组, 987 | 654 | 321 | 0 , 然后 987+654+321+0=1962, 求后三位得到散列地址为962;
除留余数法
f(key) = key mod p (p<=m)
m代表散列表长度
- p选取不好,产生冲突。
- 通常p为<=m(最好接近m)的最小质数或者不包含小于20质因子的合数。
随机数法
f(key)=random(key)
random随机函数
- 背景: 关键字长度不等。
- 当关键字为字符串,转化为某种数字来对待,比如ASCLL码或者Unicode码等。
散列冲突解决方法
- 冲突:关键字key1不等于key2,但f(key1)=f(key2)。
- 把key1和key2称为散列函数的同义词。
开放定址法
一旦冲突,寻找下一个空的散列地址,散列表大, 又称"线性探测法";
fi(key) = ( f(key) + di ) MOD m (di=1,2,3...,m-1);
<img src="https://raw.githubusercontent.com/liangxifeng833/my_program/master/images/datastruct/search-hash-function-3.png" width="588" />
优化: 二次探测法
<img src="https://raw.githubusercontent.com/liangxifeng833/my_program/master/images/datastruct/search-hash-function-4.png" width="558">
<img src="https://raw.githubusercontent.com/liangxifeng833/my_program/master/images/datastruct/search-hash-function-5.png" width="558">
还有对位移量d随机函数计算,称之为随机探测法。
再散列函数法;
fi(key) = RHi(key) (i=1,2,...k)
- RHi不同散列函数,随机使用除留、折叠、平方,每次冲突换种散列函数。
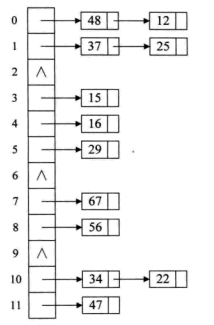
链地址法
- 将所有关键字为同义词的记录存储在一个单链表(同义词字表)中;
- 散列表中只存储所有同义词字表的头指针;
-
缺点: 查找时候需要遍历单链表, 有性能损耗;
{12,67,56,16,25,37,22,29,15,47,48,34} mod 12
- 具体可以参见:简单HashTable原理
公共溢出区法
- 冲突关键字存储到溢出表中
-
以上图有 37,48,34 是冲突的关键字,那么我们单独放在另外溢出表中, 可以将基本表和溢出表定义为两个数组;

- 散列计算后,先基本表比较。不等,到溢出表进行顺序查找。
哈希表查找
- 如果无冲突,O(1)。
- 查找平均长度取决于:
- 散列函数是否均匀
- 处理冲突的方法
- 散列表的装填因子 装填因子=填入表中的记录个数/散列表长度。(表示散列表的装满的程度) 当填入表中的记录越多,装填因子越大,产生冲突可能性越大。
- 通常设计散列表原则是: 将散列表空间设置的比查找集合大,牺牲空间换时间。
