
对于一门强类型的静态语言来说,要想通过运行时多态来隔离变化,多个实现类就必须属于同一类型体系。也就是说,它们必须通过继承的方式,与同一抽象类型建立is-a关系。
而Duck Typing则是一种基于特征,而不是基于类型的多态方式。事实上它仍然关心is-a,只不过这种is-a关系是以对方是否具备它所关心的特征来确定的。
James Whitcomb Riley在描述这种is-a的哲学时,使用了所谓的鸭子测试(Duck Test):
当我看到一只鸟走路像鸭子,游泳像鸭子,叫声像鸭子,那我就把它叫做鸭子。(When I see a bird that walks like a duck and swims like a duck and quacks like a duck, I call that bird a duck.)

Duck Test基于特征的哲学,给设计提供了强大的灵活性。动态面向对象语言,如Python,Ruby等,都遵从了这种哲学来实现运行时多态。下面给出一个Python的例子:
class Duck:
def quack(self):
print("Quaaaaaack!")
def feathers(self):
print("The duck has white and gray feathers.")
class Person:
def quack(self):
print("The person imitates a duck.")
def feathers(self):
print("The person takes a feather from the ground and shows it.")
def name(self):
print("John Smith")
def in_the_forest(duck):
duck.quack()
duck.feathers()
def game():
donald = Duck()
john = Person()
in_the_forest(donald)
in_the_forest(john)
game()
但这并不意味着Duck Typing是动态语言的专利。C++作为一门强类型的静态语言,也对此特性有着强有力的支持。只不过,这种支持不是运行时,而是编译时。
其实现的方式为:一个模板类或模版函数,会要求其实例化的类型必须具备某种特征,如某个函数签名,某个类型定义,某个成员变量等等。如果特征不具备,编译器会报错。
比如下面一个模板函数:
template <typename T>
void f(const T& object)
{
object.f(0); // 要求类型 T 必须有一个可让此语句编译通过的函数。
}
对于这样一个函数,下面的四个类均可以用来作为其参数类型。
struct C1
{
void f(int);
};
struct C2
{
int f(char);
};
struct C3
{
int f(unsigned short, bool isValid = true);
};
struct C4
{
Foo* f(Object*);
};
一旦上述模板函数实现为下面的样子,则只有C2和C3可以和f配合工作。
template <typename T>
void f(const T& object)
{
int result = object.f(0);
// ...
}
通过之前的解释我们不难发现,Duck Typing要表达的多态语义如下图所示:
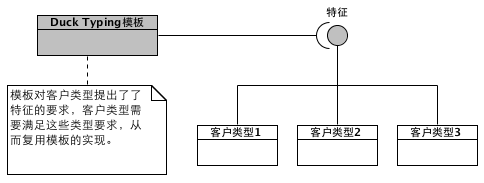
适配器:类型萃取
Duck Typing需要实例化的类型具备一致的特征,而模板特化的作用正是为了让不同类型具有统一的特征(统一的操作界面),所以模板特化可以作为Duck Typing与实例化类型之间的适配器。这种模板特化手段称为萃取(Traits),其中类型萃取最为常见,毕竟类型是模板元编程的核心元素。
所以,类型萃取首先是一种非侵入性的中间层。否则,这些特征就必须被实例化类型提供,而就意味着,当一个实例化类型需要复用多个Duck Typing模板时,就需要迎合多种特征,从而让自己经常被修改,并逐渐变得庞大和难以理解。
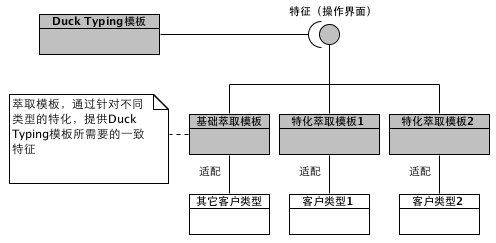
另外,一个Duck Typing模板,比如一个通用算法,需要实例化类型提供一些特征时,如果一个类型是类,则是一件很容易的事情,因为你可以在一个类里定义任何需要的特征。但如果一个基本类型也想复用此通用算法,由于基本类型无法靠自己提供算法所需要的特征,就必须借助于类型萃取。
结论
这四篇文章所介绍的,就是C++泛型编程的全部关键知识。
从中可以看出,泛型是一种多态技术。而多态的核心目的是为了消除重复,隔离变化,提高系统的正交性。因而,泛型编程不仅不应该被看做奇技淫巧,而是任何一个追求高效的C++工程师都应该掌握的技术。
同时,我们也可以看出,相关的思想在其它范式和语言中(FP,动态语言)也都存在。因而,对于其它范式和语言的学习,也会有助于更加深刻的理解泛型,从而正确的使用范型。
最后给出关于泛型的缺点:
- 复杂模板的代码非常难以理解;
- 编译器关于模板的出错信息十分晦涩,尤其当模板存在嵌套时;
- 模板实例化会进行代码生成,重复信息会被多次生成,这可能会造成目标代码膨胀;
- 模板的编译可能非常耗时;
- 编译器对模板的复杂性往往会有自己限制,比如当使用递归时,当递归层次太深,编译器将无法编译;
- 不同编译器(包括不同版本)之间对于模板的支持程度不一,当存在移植性需求时,可能出现问题;
- 模板具有传染性,往往一处选择模板,很多地方也必须跟着使用模板,这会恶化之前的提到的所有问题。
我对此的原则是:在使用其它非泛型技术可以同等解决的前提下,就不会选择泛型。
