
前面的两部分介绍基础设施即代码以及部署的方式。和虚拟机相比,Docker作为操作系统级别的虚拟化技术,特别适用微服务的部署场景。

那么我们如何使用Docker去部署微服务呢,首先应该考虑解决下面的问题:
- 对于web app,该使用什么样好的软件构建原则
- 采用何种0 downtime的部署模式
- 如何和现有的监控、日志解决方案集成
- 如何构建安全且高可用的private docker registry
使用Docker部署前的状况
在使用Docker部署前,我们已基本实现新的应用微服务化,架构上前后端分离,API通过Cloudformation去做部署,所有新的服务都部署在AWS上。一个API的持续交付的流程如下:

- 代码提交,通过PR后进入持续交付流水线
- 通过测试后生成RPM包
- 通过Packer,在一个基础镜像的启动新的服务器上安装RPM包,并生成新的AMI
- 在CI上进行自动化部署,配置文件persist到private的git repo中,避免了维护中心化服务器的成本,deploy脚本从CI中获取新生成的AMI ID,更新cloudformation template中launchConfiguration
- cloudformation触发自动化的不可变部署,完成更新。
这个流程中不好的地方在于:
- CI中打包两次,并且生成AMI时间比较长
- AMI会保存到S3中,有成本
整体来看,使用AMI去部署稍微有点重,而且一旦要从AWS退出,移植会有一点点成本。使用容器来做部署看上去可以解决这些问题,2年前Docker已经逐渐成熟,所以"领导"做了决定,咱们来用Docker替换AMI部署的方式。这样缩短了持续交付时间,同时基本避免了在不同环境的差异,可移植性大大增加,更加灵活。
12 factors app
12factors app是我们在考虑使用Docker在生产环境部署的时候参考的原则。12factors是在Heroku上部署软件时总结出来的12条好的实践,其基本的原则是:
- 使用标准化流程自动配置。
- 系统/平台最大的可移植性。
- 适合部署在现代的云计算平台,从而在服务器和系统管理方面节省资源。
- 降低开发环境和生产环境的差异降至最低,并使用持续交付实施敏捷开发。
- 可以在工具、架构和开发流程不发生明显变化的前提下实现扩展。
具体的12条原则如下:
- 基准代码:一份代码,多份部署。意思就是对于每个应用都有单独的版本管理的代码库,同时只针对主干开发,对于不同的环境test/staging/production,只针对这一份代码部署。在开发新feature时,最好不要采用feature branch的方式,因为merge的成本和测试的成本比较高,通过feature toggle去控制即可。
- 依赖:显式声明依赖。比如Ruby项目中的的Gemfile,Java项目中的Gradle配置中会声明第三方的依赖。还有类似RPM的spec文件,会显式的声明对第三方类库的依赖,比如ImageMagic。这样的文件可以放在应用代码库中,这样开发人员对于应用在生产环境中运行所需要的依赖就会比较清晰。
- 配置:在环境变量中存储配置。将代码和配置分离,我们是把每个环境的配置都放在不同的private git repo,当然你也可以用中心化的配置服务器,就是管理维护的成本比较高。
- 后端服务: 把后端服务(backing services)当作附加资源。比如邮件服务,依赖的静态文件,或者数据库。这样做的好处是和依赖的服务松耦合,其它服务的部署、scale都不会影响到应用本身,其它服务的失败,对于应用只有有限的影响,而且对于那些服务的修复,应用本身不需要再做额外的工作,如部署等。
- 构建,发布,运行: 严格分离构建和运行。直接修改处于运行状态的代码是非常不可取的做法,因为这些修改很难再同步回构建步骤。所以打包和配置分开,只有在运行时才把这两个结合起来。
- 进程: 以一个或多个无状态进程运行应用。12factors的应用的进程必须是无状态并且是不共享架构(Shared Nothing Architecture)。需要持久化的数据保存在数据库或者文件服务器(如S3)等。虽然很多服务器和LB都提供了sticky session的功能,但是最好不要使用,如果应用宕机,那么指向这台应用服务器的session都会失败,给用户不好的使用体验。
- 端口绑定:通过端口绑定提供服务。一些应用,比如Java应用,会使用Tomcat等容器,这样会有额外的依赖,12factors应用应该自我加载,比如用内嵌jetty/netty的方式启动Java/Scala应用,它们对外以后端服务的形式暴露出去,比如Rails启动的URL是
localhost:5000,最前面的LB可以建立一个简单的TCP Port Mapping80:5000,443:5000即可。 - 并发: 通过进程模型进行扩展。Apache和Nginx都有类似的工作的模式,以进程为单位,将工作分配给不同进程类型,比如web进程处理http请求,worker中运行业务代码处理具体的逻辑。除此之外,服务启动时应该将自己交给系统的自启动管理工具,System V Init、Upstart或者Systemd等,这样不需要你自己去写守护进程或者保存PID等,用统一的方式去处理启动,重启或者关闭进程。
- 易处理:快速启动和优雅终止可最大化健壮性。12 factors应用的进程必须是易处理(disposable)的,意思是说它们可以瞬间开启或停止。并且在接受到停止信号(SIGTERM)时,不再接受新的请求,并且等当前的请求处理完成再停止服务。
- 开发环境与线上环境等价: 尽可能的保持开发,预发布,线上环境相同。"It works on my machine"是程序员中间流行的一个笑话,如果可以通过类似Docker这样的容器技术进行打包的话,可以尽量的避免这个问题。如此,你可以让错误更早的呈现,减少反馈的时间,让上线更为顺利。
- 日志: 把日志当作事件流。日志对于追踪应用运行的状况以及一些业务分析非常重要。有些时候日志会被存在服务器硬盘上,但是对应的处理这些日志,你需要添加额外的配置,比如logrotate之类,同时你对服务器的磁盘也产生了依赖。12 factors提倡将日志当做事件流,应用的输入直接写入stdout和stderror,然后将它们发送到诸如ElasticSearch以及Splunk之类的日志服务器中。还有一个好处是,开发人员可以直接从Splunk查找日志,而不需要运维去将日志从服务器拷贝下来,也不需要运维人员给开发人员授权访问生产环境的服务器的ssh访问权限。
- 管理进程: 后台管理任务当作一次性进程运行。典型的例子就是schema migration或者data migration。这样的任务应该和生产环境同一个环境下运行,并且必须和生产代码保持一致。
如果回头看下我们使用AMI时候的状态,很多已经是符合12 factors原则了,但是我们需要在日志处理等方面使用Docker继续改进。
使用Docker的一些考量
我们原本在生产环境下运行的服务,需要集成newrelic对服务器和应用做监控(NewrelicSysmon和Newrelic Agent),同时日志需要发送到Splunk indexer集群。基于已有的基础以及12 factors原则,应用以容器的方式在服务器上运行的形式如下:

- launchConfiguration中只需要一个存在Docker运行环境的基础AMI
- Instance启动后,在user-data顺序启动日志收集的容器(基于fluentd),运行Nginx容器以及app的容器
- 其中几个容器必须都运行在同一网络下,确保能连接到日志收集容器,并在输出日志时tag自己的身份
- fluentd将接受到的日志,以及host instance的syslog一起通过splunk plugin发往splunk的fowarder,再由其转发给splunk indexer。
如此则应用/服务本身对于服务器除了计算资源外,没有任何的依赖,同时部署的方式也沿用基于cloudformation的immutable deployment,还有获得了高可移植性以及多个环境的最大一致性。
高可用且安全的private docker registry
要使用Docker部署,就得保证私有的docker registry的可用性,以及安全。使用用户名密码的方式做验证是不太合适的,因为这样管理和维护的成本很高。docker registry v2支持 Bearer Token(JWT Token)的方式去做验证。
如果你曾经往dockerhub push过镜像,那么当你在命令行使用docker login的时候,它做的事情是在~/.docker/config.json里面生成下面的格式的配置:
{
"auths": {
"https://index.docker.io/v1/": {
"auth": "Base64_encoded"
}
}
}
这里auth中包含的字符串如果你用base64解码后,可以惊奇的发现那里就是自己的用户名和密码:)。本地docker去访问docker hub时,这个auth就是Authorization: - header中的部分,然后docker hub的registry再对这个进行验证和授权,确认你可以进行的操作。
对于高逼格企业内部的私有docker registry,是不会用这样的方式进行验证的。一个合理的方式是使用JWT token。 JWT是允许按照声明的格式去发布一个加密/签名过的token,当用户通过身份验证后,它会生成下面的格式:
指明加密算法(支持对称型以及非对称型加密)以及token类型的Header:
{
"typ": "JWT",
"alg": "ES256",
}
包含用户名(sub),以及token过期时间exp,权限act等的Payload:
{
"exp": 1484102411,
"nbf": 1484012411,
"iat": 1484012411,
"sub": "itsasecret",
"aud": [
"my.awesome.internal.docker.registry"
],
"act": [
"read"
]
}
Signature部分,根据算法的不同,如果是对称型加密算法,那么签名的部分知识对Header、PayLoad的base64编码后的签名,而使用RSA算法,则是使用私钥去加密Header/PayLoad部分的内容后用base64编码的结果。然后这几部分用.连接起来,构成了整个的token,如下:
token: eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiIsImtpZCI6IlBZWU86VEVXVTpWN0pIOjI2SlY6QVFUWjpMSkMzOlNYVko6WEdIQTozNEYyOjJMQVE6WlJNSzpaN1E2In0.eyJpc3MiOiJhdXRoLmRvY2tlci5jb20iLCJzdWIiOiJqbGhhd24iLCJhdWQiOiJyZWdpc3RyeS5kb2NrZXIuY29tIiwiZXhwIjoxNDE1Mzg3MzE1LCJuYmYiOjE0MTUzODcwMTUsImlhdCI6MTQxNTM4NzAxNSwianRpIjoidFlKQ08xYzZjbnl5N2tBbjBjN3JLUGdiVjFIMWJGd3MiLCJhY2Nlc3MiOlt7InR5cGUiOiJyZXBvc2l0b3J5IiwibmFtZSI6InNhbWFsYmEvbXktYXBwIiwiYWN0aW9ucyI6WyJwdXNoIl19XX0.QhflHPfbd6eVF4lM9bwYpFZIV0PfikbyXuLx959ykRTBpe3CYnzs6YBK8FToVb5R47920PVLrh8zuLzdCr9t3w
JWT的工作流程如下:
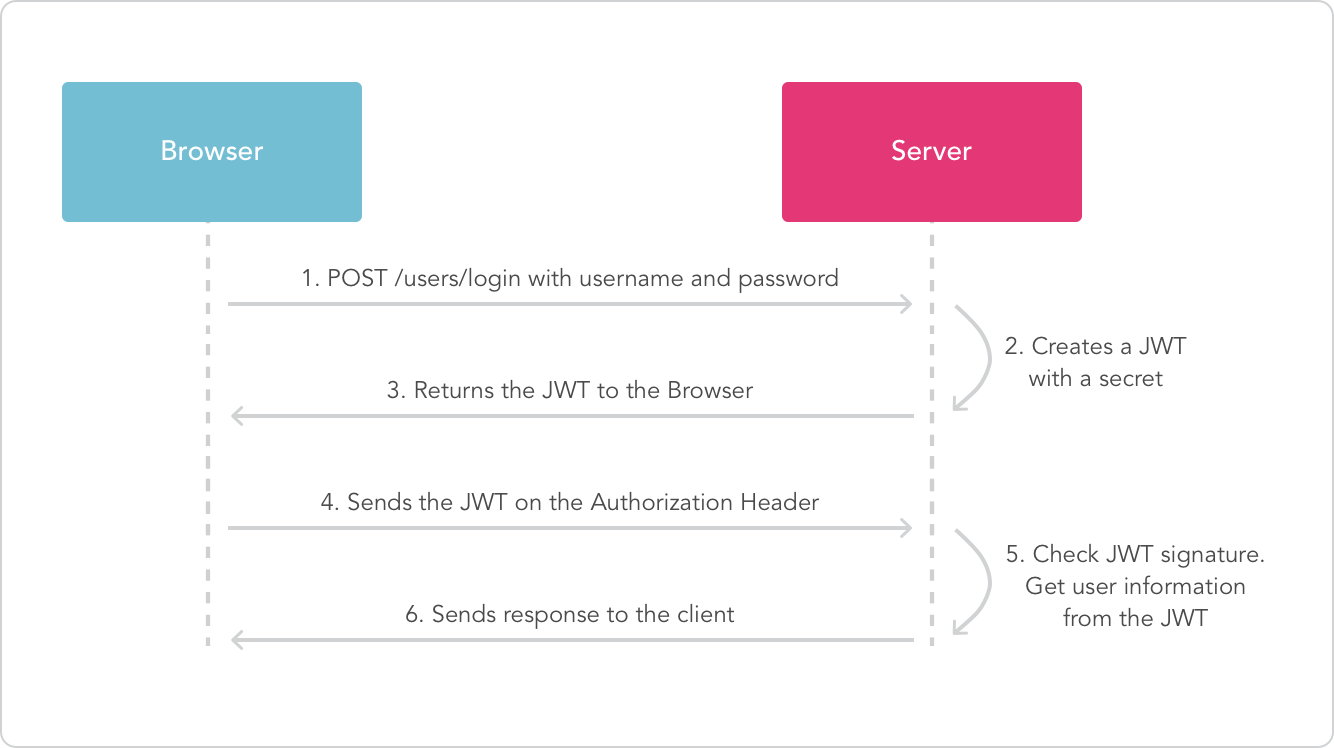
当你使用这个token向registry发起请求时,其header中会包含Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiIsImtpZCI6IkJWM0Q6MkFWWjpVQjVaOktJQVA6SU5QTDo1RU42Ok40SjQ6Nk1XTzpEUktFOkJWUUs6M0ZKTDpQT1RMIn0.eyJpc3MiOiJhdXRoLmRvY2tlci5jb20iLCJzdWIiOiJCQ0NZOk9VNlo6UUVKNTpXTjJDOjJBVkM6WTdZRDpBM0xZOjQ1VVc6NE9HRDpLQUxMOkNOSjU6NUlVTCIsImF1ZCI6InJlZ2lzdHJ5LmRvY2tlci5jb20iLCJleHAiOjE0MTUzODczMTUsIm5iZiI6MTQxNTM4NzAxNSwiaWF0IjoxNDE1Mzg3MDE1LCJqdGkiOiJ0WUpDTzFjNmNueXk3a0FuMGM3cktQZ2JWMUgxYkZ3cyIsInNjb3BlIjoiamxoYXduOnJlcG9zaXRvcnk6c2FtYWxiYS9teS1hcHA6cHVzaCxwdWxsIGpsaGF3bjpuYW1lc3BhY2U6c2FtYWxiYTpwdWxsIn0.Y3zZSwaZPqy4y9oRBVRImZyv3m_S9XDHF1tWwN7mL52C_IiA73SJkWVNsvNqpJIn5h7A2F8biv_S2ppQ1lgkbw,registry前的反向代理服务器如Nginx上,可以运行jwt验证的模块,用public key解密token,并验证内容完整性、是否过期等,完成后再将内容传递给registry,registry根据请求类型以及
"act": [
"read"
]
判断是否有足够的授权,之后在允许用户pull image。
这是从安全的角度考虑使用JWT+RSA去验证用户身份以及授权,好处是维护的成本比较低,同时token在一段时间内就过期,兼顾了安全型。
另一方面,从可用性的角度考虑,我们使用了S3作为registry的storage backend。最终的private docker registry架构如下:

- 当其中一个AWS账户下的某个用户/role需要访问registry权限时,你可以按照固定的格式修改config repo,提交PR,merge后自动部署到一个config s3 bucket。
- 一个定时运行的Lambda函数会从这个bucket读取配置文件,并为具体的用户/role生成访问的token以及授权,并将token保存在另外一个token的s3 bucket中,同时授予这个用户/role访问这个token文件的权限。
- 用户在使用时,首先用自己的用户名密码获得session,之后从token的bucket中下载token文件,通过
docker login覆写~/.docker/config.json,再进行pull/push docker image的操作。 - 在服务器(EC2 instance)上部署时需要给instance绑定instanceProfile让它可以从token的bucket拿到这个token
- 为了加快访问速度,可以直接从保存docker image的S3 bucket中拿到docker image的tar包
总结
目前,我们在生产环境已经有100个左右的微服务使用docker去做部署(基于我们定制的一个类PaaS的部署工具)。如果我们回头再来看这样的使用docker的运行应用的模式,会发现似乎应用只需要服务器有运行时环境以及计算资源,如果我的应用逻辑简单,那么有没有可能由这样一种服务:
- 它有一些standby的具有运行代码运行时环境的容器
- 可以在请求过来时,以很短的时间(ms级别)内,启动包含/部署代码的容器然后处理请求。
这这样的服务就像PaaS一样,基础设施对我不可见,服务器维护成本为零,同时只要关注在业务代码即可。这就是现在经常提到的Serverless的概念,下一节我们就来介绍Serverless、其目前适用的场景以及目前唯一比较成熟的Serverless服务AWS Lambda。
