
认识Task Flow
TaskFlow是一个python库,用来简化任务的执行管理,同时,实现任务的一致性、可扩展和可靠性。TaskFlow支持创建不同的 task,并以声明的方式集成到一个 flow 中,这些 flow 会通过 engine 执行、停止、继续和恢复。
优点
- 弹性的增加状态
- 自然声明构造
- 简单可测试(每个 task 只做一件事)
- 工作流可插拔
- 容错性
- 简单的故障恢复
概念示例
伪代码展示了 flow 类似于SQL事务的执行模式
START TRANSACTION task1: call nova API to launch a server || ROLLBACK task2: when task1 finished, call cinder API to attach block storage to the server || ROLLBACK ...perform other tasks... COMMIT
why
OpenStack 的代码正在有组织的增长,但是如果进程被意外中断,却没有一个可以安全恢复或回滚代码的标准;大多数项目并没有使 task 可以重启或恢复,简单的挑高或恢复的场景在今天的代码里已几乎不可能。通过Taskflow的推广,甚至在没有HA的情况下,使OpenStack变的可信和可靠。
一些使用场景
服务停止、更新、重启
目前Openstack的大部分服务都没有对服务的强制停止做任何处理,使任务处于不可调和的状态。比如,一个任务在运行过程中被终止,可能会变为不可恢复的状态,或成为遗留资源。TaskFlow可以跟踪任务的关联状态,当服务重启后,可以很容易的恢复或者回滚。Orphaned resources(僵尸资源)
由于现在OpenStack的项目缺乏事务语义,所以会留下一些资源成为孤儿状态,或ERROR的状态,在自动化系统(Heat)情况下,这种状况是非常不能令人接收的,因为非常难分析哪些是要被清除的孤儿资源。
Taskflow提供其以任务为导向的模型将能正确地追踪资源的变动,这就容许在一些资源上的动作可以自动地被撤销,以确定没有资源被称为“僵尸”。Metrics and history(度量和历史)
当OpenStack服务被组织进 task 和 flow 的对象和模式时,通过将记录 task 在运行时的度量/历史,这些服务便自动获得了简单的增加度量报告和历史操作的能力。进度/状态跟踪
Openstack中,有很多场景需要记录和跟踪任务的进度,TaskFlow提供了一种内建的通知机制实现任务进度的跟踪。
设计
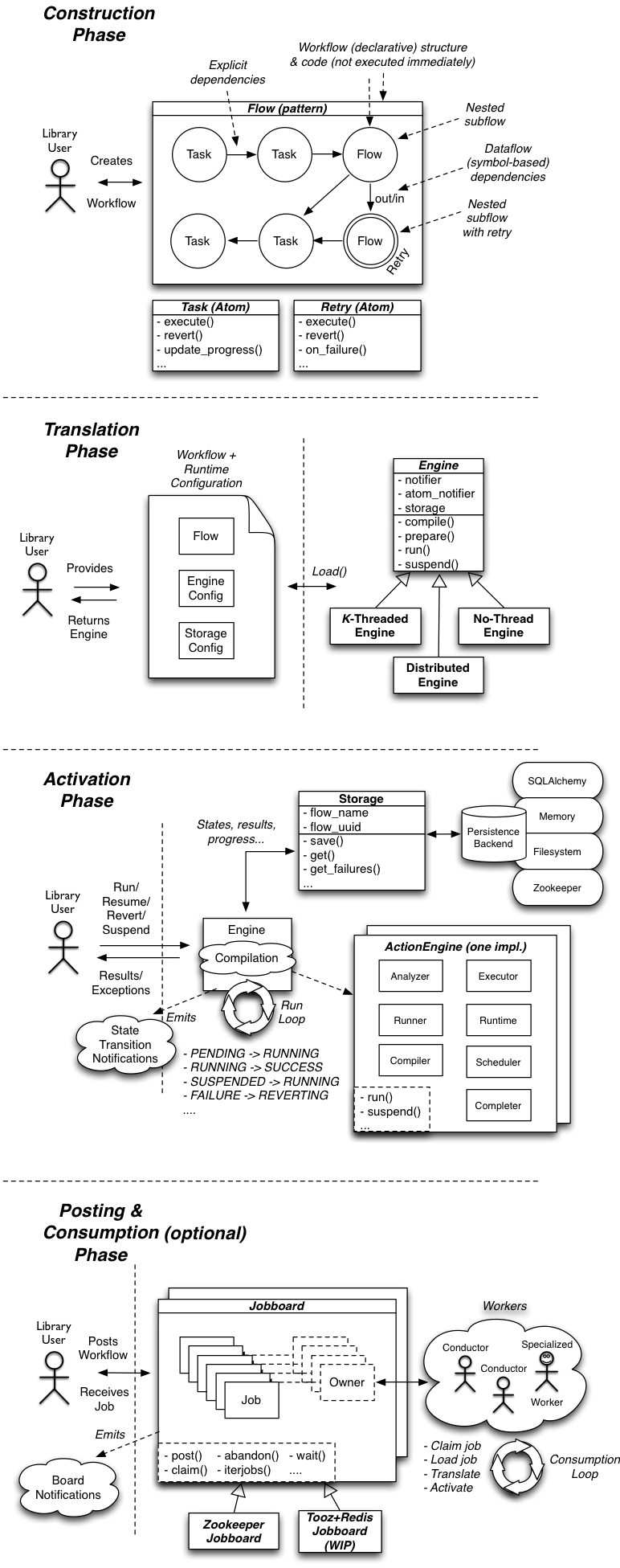
构成
- Atoms
TaskFlow的最小单元,是其他类型的基础。atom是一种命名对象,通过操作输入数据实现流程中的一个动作,或者输出一个处理结果。我理解atom是一个抽象概念,其中定义了任务、操作和数据。 - Task
task派生于一个atom,包括一个 execute & rollback序列每个task都继承自Task,其中定义了一系列的属性和方法。
- Retry
retry也是派生于一个atom,是一个特殊的单元,实现对错误的处理,控制flow的异常情况,必要时,能够以其他参数重试另一个atom。retry基类的派生类必须提供on_failure()方法,实现对异常的处理。

参考
TaskFlow官方文档
An Introduction to OpenStack TaskFlow with Python
