
简介
在 Java 并发编程中,volatile 是经常用到的一个关键字,它可以用于保证不同的线程共享一个变量时每次都能获取最新的值。volatile 具有锁的部分功能并且性能比锁更好,所以也被称为轻量级锁。下面具体分析 volatile 的用法及原理,涉及到内存模型、可见性、重排序以及伪共享等方面。
内存模型
在深入理解 volatile 之前,先了解一些计算机的内存模型。当 CPU 执行运算的时候,需要从内存中取数据,由于 CPU 的运算速度远远快于内存的读取速度,所以 CPU 需要等数据,这个过程就浪费了 CPU 的时间。为了提高效率, 在 CPU 和内存之间会有缓存(一般有三级缓存),缓存的读写速度高于内存,容量也会比内存小得多。当 CPU 读数据的时候会先从缓存中读,如果缓存未命中则会去内存读,并把数据放到缓存中,写数据的时候也会先写缓存,在适当的时候再将缓存中的数据刷新到内存中。
缓存的使用提高了 CPU 的运行效率,但是对于多核处理器会有一些问题。如果某个内存地址的数据同时被两个 CPU 缓存,其中一个 CPU 修改了这个地址的值,无论这个值是写入到了缓存中还是被刷新到了内存中,只要另一个 CPU 依然使用其缓存中的值,那还是旧值。因此对于多线程来说,需要一些手段来保证数据的一致性。
对于 Java 来说,程序运行在 JVM 上,JVM 提供了类似的内存抽象模型,如下图所示。
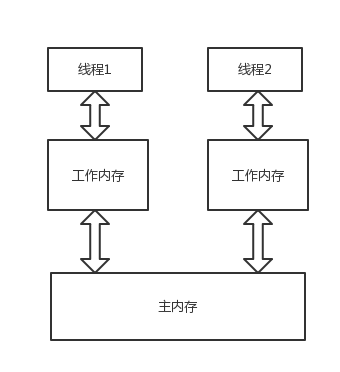
每个线程有自己的工作内存,相当于缓存,所有的线程共享主内存,相当于系统中的内存。线程之间往往会有共享变量,为了保证共享变量的可见性,需要采用 java 提供的并发技术。对于单个变量的可见性来说,volatile 是一种有效的机制。
内存可见性
先看下面的一段代码:
int a = 1;
boolean flag = false;
int b = 3;
// 线程1
a = 2;
flag = true;
// 线程2
if (flag) {
b = a;
}
上面的代码如果线程 1 执行后,线程 2 中的 flag 能立刻看到 flag 的新值吗?根据上面介绍的 Java 内存模型可以知道,答案是不一定。那么如何保证当线程 1 更新 flag 之后,线程 2 能够读取到最新的值呢?其实很简单,只需要给 flag 添加 volatile 修饰符。
那么 volatile 是如何做到的呢? 我们想一想,根据 Java 内存模型,要实现这种功能该怎么做?应该是两步:1. 当线程 1 写 volatile 变量的时候,将这个值从缓存刷新到主内存中 2. 当线程 2 读取 volatile 变量的时候,将本地的工作内存置为无效,从主内存读取新值。
其实 volatile 的实现正是以上的原理,对于一个 volatile 变量的写操作会有一行以 lock 作为前缀的汇编代码。这个指令在多核处理器下会引发两件事:
- 将当前处理器缓存行的数据写回到主内存
- 这个写回内存的操作会使在其它 CPU 里缓存了该内存地址的数据无效
lock 前缀的指令会锁住系统总线或者是缓存,目的是保证在同一时间只有一个 CPU 会修改数据,使得修改具有原子性。根据 缓存一致性 协议, CPU 通过嗅探技术保证它的内部缓存、内存和其它处理器的缓存的数据的一致性。例如,一个处理器检测其它处理器打算写内存地址,而这个地址当前处于共享状态,那么正在嗅探的处理器将使它的缓存行无效,在下次访问相同的内存地址时,强制执行缓存行填充。
禁止重排序
volatile 除了保证内存可见性,还可以禁止重排序。在了解重排序之前,先看一段代码:
class Singleton {
private static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
上面的代码一看就是单例模式,并且使用了双重加锁提高效率。稍微有经验的程序员还会发现,上面的写法是不正确的,应该给 instance 添加 volatile 修饰。那么为什么需要 volatile 呢?
其实问题出在 instance = new Singleton(); 这一行,这里是创建 Singleton 对象的地方,其实这里可以看成三个步骤:
- memory = allocate(); //1: 分配对象的内存空间
- ctorInstance(memory); //2: 初始化对象
- instance = memory; //3: 设置 instance 指向刚分配的内存地址
上面的伪代码可能会被重排序。什么是重排序?编译器以及处理器有时候会为了执行的效率改变代码的执行顺序,这个被称为重排序。上面的三个步骤可能会被重排序为下面的步骤:
- memory = allocate(); //1: 分配对象的内存空间
- instance = memory; //2: 设置 instance 指向刚分配的内存地址
// 注意:此时对象还没有被初始化 - ctorInstance(memory); //3: 初始化对象
在这种情况下,当一个线程执行到 instance = memory; 的时候,对象还没有被初始化,另一个线程也调用了 getInstance 方法,发现 instance 引用不为 null,就会认为这个对象已经创建好了,从而使用了未初始化的对象。
为什么 volatile 可以避免上面的问题?其实是因为 volatile 会禁止重排序,方法是插入了内存屏障,具体原理较复杂,这里就不深入分析了。
伪共享
CPU 缓存是以缓存行为单位进行存取的,一般一个缓存行是 64 字节,如果两个 volatile 变量被缓存在同一个缓存行,并且有多个 CPU 缓存了同一行数据,那么会出现 伪共享 的问题,造成性能问题。
例如,CPU A 以及 CPU B 都在同一个缓存行缓存了共享变量 X 和 Y,如果 CPU A 修改了 X,那么 CPU B 中的缓存行也就失效了,如果 CPU 只是需要读取 Y ,却因为 X 使得整个缓存行都要重新读取,这就不划算了,这叫做伪共享。
解决伪共享主要是让不同的 volatile 变量不要缓存到同一个缓存行,可以利用填充技术来解决,具体可以参考这篇文章:Java中的伪共享以及应对方案
总结
volatile 作为一个轻量级的锁可以实现内存可见性以及禁止重排序,常用于修饰标记变量以及双重加锁的场景等。需要注意的是,volatile 用于保证一个变量的可见性,但是对于 i++ 这种复合操作是无法保证原子性的。另外,注意伪共享问题可以进一步提升性能。
参考
- 《Java 并发编程的艺术》
