
上次爬了教务处的成绩,接下来想去爬一爬知乎娘,好像大家都很喜欢爬知乎娘,GitHub上貌似已经有人把获取各种知乎数据的操作封装好了:zhihu-python ,但是良辰表示还是想自己试一试,我就爬点简单的,难度大的我也不会,我瞄准的是我自己关注的人的数据,差不多就这些东西:
那么下面开始分析,要拿到这个数据肯定是要先登陆的,那么先找到登陆界面:关注者 / 提问 / 回答 / 赞同

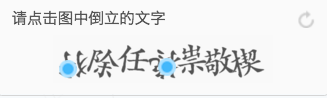


现在理一下思路,我们要登录知乎要传递的数据如下:
- _xsrf()用于防伪登陆
- password- captcha 验证码
- phone_num/email 不同登陆方式传递的东西不同
phone_num/email以及passsword都需要自己输入,这个好办,我们需要解决如何获取 _xsrf和captcha 的问题,先解决 _xsrf,这个更简单一点,我们在知乎登陆页面 右键查看网页源代码,直接搜_xsrf:
<div class="view view-signin" data-za-module="SignInForm">
<form><input type="hidden" name="_xsrf"
value="cf1ee28f15cea5dba3243a1c31a1b284"/><div class="group-inputs">
我们要做的就是解析出这个元素,直接上代码:
# 构造 Request headers
# 登陆的url地址
logn_url = 'http://www.zhihu.com/#signin'
session = requests.session()headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.82 Safari/537.36',}
content = session.get(logn_url, headers=headers).content
soup = BeautifulSoup(content, 'html.parser')def getxsrf():
return soup.find('input', attrs={'name': "_xsrf"})['value']

当我把这个Request URL输入浏览器中就会转到这个验证码图片的界面,说明这个验证码是我们加载这个页面时候,浏览器向服务器发出请求然后下载下来的,那么现在我们有了URL地址:

try:
from PIL import Image
except:
pass
# 获取验证码
def get_captcha():
t = str(int(time.time() * 1000))
captcha_url = 'http://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
r = session.get(captcha_url, headers=headers)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
f.close()
# 用pillow 的 Image 显示验证码
# 如果没有安装 pillow 到源代码所在的目录去找到验证码然后手动输入
try:
im = Image.open('captcha.jpg')
im.show()
im.close()
except:
print(u'请到 %s 目录找到captcha.jpg 手动输入' % os.path.abspath('captcha.jpg'))
captcha = input("please input the captcha\n>")
return captcha
这里获取验证码的代码来自GitHub上的fuck-login项目,在此表示感谢,接下里就是写一个方法判断用户是使用了哪一种登陆方式,然后传递相应的数据:
def login(secret, account):
# 通过输入的用户名判断是否是手机号
if re.match(r"^1\d{10}$", account):
print("手机号登录 \n")
post_url = 'http://www.zhihu.com/login/phone_num'
postdata = {
'_xsrf': getxsrf(),
'password': secret,
'remember_me': 'true',
'phone_num': account,
}
else:
print("邮箱登录 \n")
post_url = 'http://www.zhihu.com/login/email'
postdata = {
'_xsrf': getxsrf(),
'password': secret,
'remember_me': 'true',
'email': account,
}
try:
# 不需要验证码直接登录成功
login_page = session.post(post_url, data=postdata, headers=headers)
login_code = login_page.text
print(login_page.status)
print(login_code)
except:
# 需要输入验证码后才能登录成功
postdata["captcha"] = get_captcha()
login_page = session.post(post_url, data=postdata, headers=headers)
login_code = eval(login_page.text)
print(login_code['msg'])
# 这部分代码同样来自[**fuck-login**](https://github.com/xchaoinfo/fuck-login)项目,我偷了很多懒,囧

因为网页有时候会跳转,这里打钩之后新跳转的页面的信息就不会覆盖之前接受到的信息,然后找到我关注的人,URL地址是:
最开始我走了弯路,我以为直接在这个页面解析出我关注的人的信息就行,所以一开始我是这么做的,查看网页源代码,这里随便找一个我关注的人的信息:
<a title="死者代言人"
data-hovercard="p$t$forensic"
class="zm-item-link-avatar"
href="/people/forensic">
</a>
<div class="zm-list-content-medium">
<h2 class="zm-list-content-title"><a data-hovercard="p$t$forensic" href="https://www.zhihu.com/people/forensic" class="zg-link author-link" title="死者代言人"
>死者代言人</a><span class="icon icon-badge-best_answerer icon-badge" data-tooltip="s$b$优秀回答者"></span></h2>
<div class="ellipsis">
<span class="badge-summary">优秀回答者</span>
<span class="bio">不养喵的爱喵法医。</span>
</div>
<div class="details zg-gray">
<a target="_blank" href="/people/forensic/followers" class="zg-link-gray-normal">35968 关注者</a>
/
<a target="_blank" href="/people/forensic/asks" class="zg-link-gray-normal">2 提问</a>
/
<a target="_blank" href="/people/forensic/answers" class="zg-link-gray-normal">305 回答</a>
/
<a target="_blank" href="/people/forensic" class="zg-link-gray-normal">51278 赞同</a>
</div>
然后在对比另一条:
<a title="陈亦飘"
data-hovercard="p$t$chen-yi-piao"
class="zm-item-link-avatar"
href="/people/chen-yi-piao">

</a>
<div class="zm-list-content-medium">
<h2 class="zm-list-content-title"><a data-hovercard="p$t$chen-yi-piao" href="https://www.zhihu.com/people/chen-yi-piao" class="zg-link author-link" title="陈亦飘"
>陈亦飘</a></h2>
<div class="ellipsis">
<span class="bio">音乐和电影是我的爱与慈悲</span>
</div>
<div class="details zg-gray">
<a target="_blank" href="/people/chen-yi-piao/followers" class="zg-link-gray-normal">74469 关注者</a>
/
<a target="_blank" href="/people/chen-yi-piao/asks" class="zg-link-gray-normal">0 提问</a>
/
<a target="_blank" href="/people/chen-yi-piao/answers" class="zg-link-gray-normal">80 回答</a>
/
<a target="_blank" href="/people/chen-yi-piao" class="zg-link-gray-normal">315971 赞同</a>
</div>
要分解出这些元素,只要找出他们的共同点,当时机智如我一眼就发现每一个我关注的人的名字都有这么一行元素:
class="zm-item-link-avatar"
而且都包含在一个<a></a>标签里面,这就好办了,使用BeautifulSoup先分解出每一个我关注的人的名字:
def getdetial():
followees_url = 'https://www.zhihu.com/people/GitSmile/followees'
followees_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Referer': 'https://www.zhihu.com/people/GitSmile/about',
'Upgrade-Insecure-Requests': '1',
'Accept-Encoding': 'gzip, deflate, sdch, br'
}
myfollowees = session.get(followees_url, headers=followees_headers)
mysoup = BeautifulSoup(myfollowees.content, 'html.parser')
print(mysoup.find('span', attrs={'class': 'zm-profile-section-name'}).text)
然后继续观察,突破点依然在这个<a></a>标签,拿"陈亦飘"的信息做个例子,看官们看这里面是不是有个href="/people/chen-yi-piao,然后看一下她的相关信息:
<a target="_blank" href="/people/chen-yi-piao/followers" class="zg-link-gray-normal">74469 关注者</a>
/
<a target="_blank" href="/people/chen-yi-piao/asks" class="zg-link-gray-normal">0 提问</a>
/
<a target="_blank" href="/people/chen-yi-piao/answers" class="zg-link-gray-normal">80 回答</a>
/
<a target="_blank" href="/people/chen-yi-piao" class="zg-link-gray-normal">315971 赞同</a>
发现没有,每一个信息里面的href元素都是我们最开始看到的/people/chen-yi-piao元素加上一些字符串组成的,那么我就可以在这上面做点文章:
获取详细信息
def getdetial():
followees_url = 'https://www.zhihu.com/people/GitSmile/followees'
followees_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Referer': 'https://www.zhihu.com/people/GitSmile/about',
'Upgrade-Insecure-Requests': '1',
'Accept-Encoding': 'gzip, deflate, sdch, br'
}
myfollowees = session.get(followees_url, headers=followees_headers)
mysoup = BeautifulSoup(myfollowees.content, 'html.parser')
print(mysoup.find('span', attrs={'class': 'zm-profile-section-name'}).text)
for result in mysoup.findAll('a', attrs={'class': 'zm-item-link-avatar'}):
print(result.get('title'))
# 解析出href元素信息
href = str(result.get('href'))
# 关注者
print(mysoup.find('a', attrs={'href': href + '/followers'}).text)
# 提问
print(mysoup.find('a', attrs={'href': href + '/asks'}).text)
# 回答
print(mysoup.find('a', attrs={'href': href + '/answers'}).text)
# 赞同
print(mysoup.find('a', attrs={'href': href, 'class': 'zg-link-gray-normal'}).text + '\n')
上面的代码应该很简单了,看一看就能看懂,然后就我信心满满地在PyCharm上输出的时候,发现来来回回只输出20条信息,也就是说,我关注了26人,但是控制台只输出了20个人的信息,然后我就上网查,发现不止一个人有我这样的疑问,当然也多亏了前人踩坑,网上给出来的答案是知乎获取关注的人的时候使用了AJAX技术,也就是动态加载,但是这一部分代码不会再网页Html代码中显示出来,所以为了获取其他关注的人的信息我这里要另辟蹊径。
然后我翻看我关注的人的信息的时候,在开发者面板抓到这么一条POST信息:

这条POST之后下面刷出来的图片是我关注的人的头像并且这些头像在我之前看到的20条数据里面是没有的,加上我总共就关注了27个人,所以我有理由相信这个Post就是浏览器向服务器发送请求的Post,看一下Post的信息:

一个偏移量(offset),一个哈希值(hash_id)外加一个"order_by":"created"的键值对,这里偏移量很好理解,这个"hash_id"据我多次登陆发现是一个不变的值,或者说每一台电脑或许精确一点每一个浏览器都会有这么一个给定的值,照抄,那么改进后的代码如下:
# 获取所有关注的人的信息
def getallview():
nums = 27 # 这个是我关注的人数
followees_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Referer': 'https://www.zhihu.com/people/GitSmile/followees',
'Origin': 'https://www.zhihu.com',
'Accept-Encoding': 'gzip, deflate, br',
'CG - Sid': '57226ad5 - 793b - 4a9d - 9791 - 2a9a17e682ef',
'Accept': '* / *'
}
# 序号
count = 0
for index in range(0, nums):
fo_url = 'https://www.zhihu.com/node/ProfileFolloweesListV2'
m_data = {
'method': 'next',
'params': '{"offset":' + str(
index) + ',"order_by":"created","hash_id":"de2cb64bc1afe59cf8a6e456ee5eaebc"}',
'_xsrf': str(getxsrf())
}
result = session.post(fo_url, data=m_data, headers=followees_headers)
dic = json.loads(result.content.decode('utf-8'))
li = dic['msg'][0]
mysoup = BeautifulSoup(li, 'html.parser')
for result in mysoup.findAll('a', attrs={'class': 'zm-item-link-avatar'}):
print(index + 1)
print(result.get('title'))
href = str(result.get('href'))
print(mysoup.find('a', attrs={'href': href + '/followers'}).text)
print(mysoup.find('a', attrs={'href': href + '/asks'}).text)
print(mysoup.find('a', attrs={'href': href + '/answers'}).text)
print(mysoup.find('a', attrs={'href': href, 'class': 'zg-link-gray-normal'}).text + '\n')
count += 1
print('一共关注了 %d人' % count)
放上程序的入口:
if __name__ == '__main__':
if isLogin():
print('您已经登录')
else:
account = input('请输入你的用户名\n> ')
secret = input("请输入你的密码\n> ")
login(secret, account)
getallview()
看一下实际效果:

写在结尾
虽然简单,但是提供了一些初学者的思路,下一次准备爬一些知乎上的图片,好像很多人都热衷于这种事,嘻嘻,荆轲刺秦王。
